
Data Management Interface (DMI)
Control File-executable DMI
The Data Management Interface (DMI) provides an efficient means of transferring large amounts of data between RiverWare and an external data source or sink. There are two directions in which a DMI can send data:
• An Input DMI, which transfers data from an external data source to RiverWare.
• An Output DMI, which transfers data from RiverWare to an external data sink.
Introduction
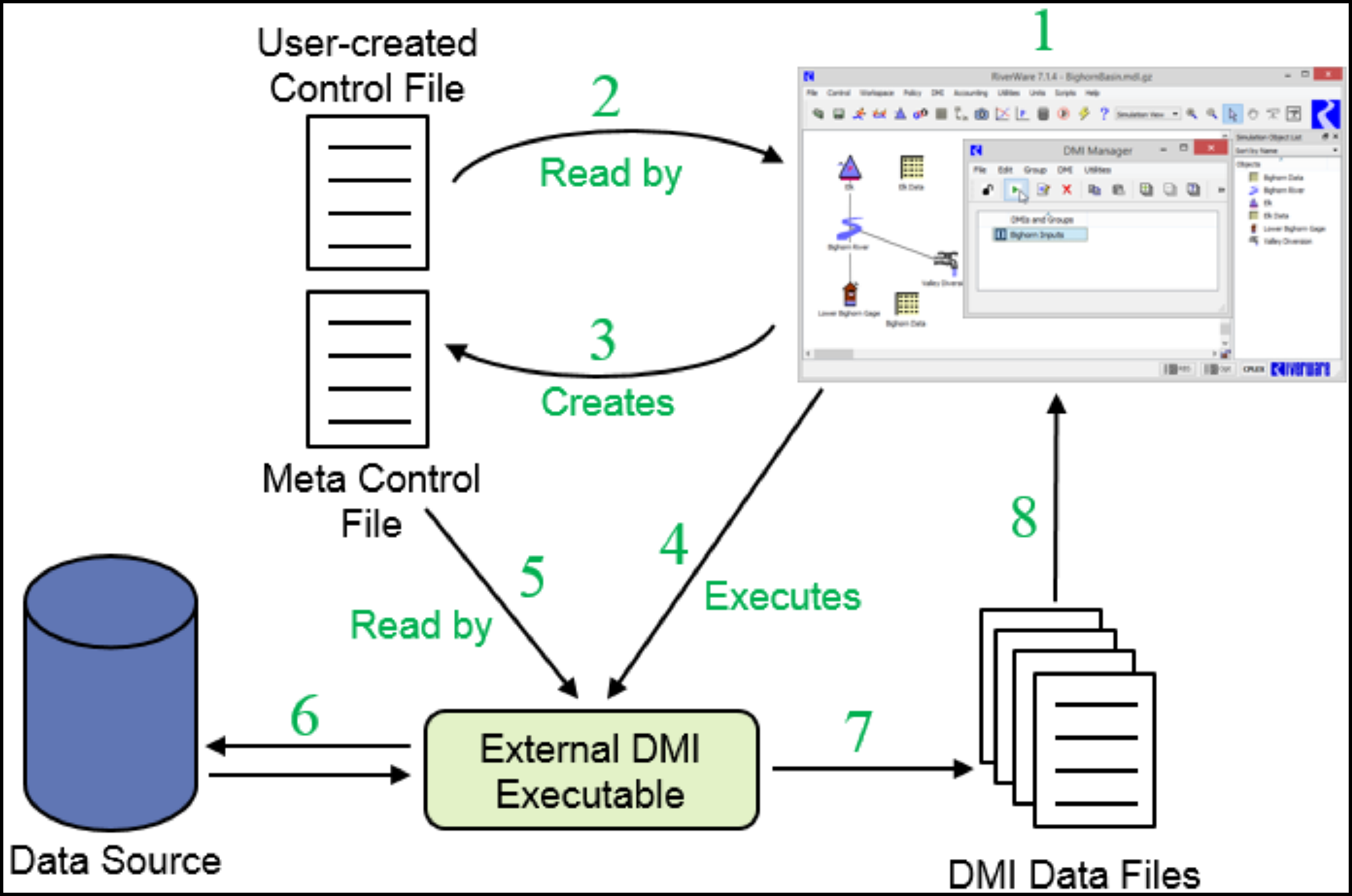
The Control File-Executable DMI consists of several components. Refer to Figure 2.1 for the relation between these components.
• The User-specified Control File is created by the user and contains a list of slots which the user wants imported or exported from the RiverWare model. The control file is an ASCII file which maps data between object.slots in the Workspace and data files
• The External DMI Executable is a separate software component which is called by the RiverWare DMI facility. For import DMIs, this external executable provides the data files which RiverWare loads into the model. For output DMIs, the external executable processes data files exported by RiverWare and performs such functions as saving the data in the database, reprocessing the data into reports, and preparing the data for use by statistical analysis programs.
• The RiverWare DMI Data Files are a set of files used to transfer the data to and from the RiverWare model. Each of these files contains the data for a single slot in the model. The files are created by either the External DMI Executable or RiverWare, depending on whether it is an input or an output DMI.
As shown in Figure 2.1, the user must minimally create a control file and an executable. Following is an example of how the DMI works. In this example we assume it is an Input DMI, but it is the same, just reversed for an Output DMI.
1. The user Invokes the Input DMI. RiverWare verifies the DMI to make sure it is valid.
2. RiverWare reads the user Control File and resolves all wild carding.
3. RiverWare writes the Meta Control File which has a fully specified line for each slot in the Control File.
4. RiverWare runs the External DMI Executable.
5. The executable reads the Meta Control File.
6. The executable interacts with the Data Source (i.e. the database) to retrieve the data.
7. The executable creates the DMI Data Files. .
8. Once the executable is complete, RiverWare reads the DMI Data Files and places data in the slots.
Note: Alternatively, the user can create the DMI Data Files separately without using an executable. In this case steps 4-7 will be skipped
Figure 2.1 Control File - Executable Input DMI schematic
Control File
The control file is an ASCII file which the user provides. The purpose of the control file is as follows:
• Map between object.slots in the Workspace and data files. In the case of an import DMI, data is imported from the data files to the object.slots; in the case of an export DMI, data is exported from the object.slots to the data files.
• Provide information about the data files.
Each control file entry contains three pieces of information:
• An object.slot specification.
• One or more file names listed as file = name
• Optional keyword = value pairs.
The control file format is:
object.slot: file=name keyword=value keyword=value ...
If a file name contains spaces then it must be enclosed in double quotations marks (“), for example:
object.slot: file=”file name” keyword=value keyword=value ...
The DMI must also be configured to allow spaces in file paths; see “Allow Spaces in File Paths” for details.
Object.Slot Specifications
The object.slot specifications indicate which slots will import from or export to data files. There are four ways of specifying the object:
• <object name> - A specific object name, e.g., “FtLoudoun,” which matches the object with that name. Aggregate object elements are specified as <aggregate name>:<element name>.
• <object type> - An object type, e.g., “LevelPowerReservoir,” which matches all objects of that type.
• <sub-basin name> - A sub-basin name, which matches all objects in the sub-basin.
• * - A wild card which matches all objects of all types.
There are three ways of specifying the slot:
• <slot name> - A specific slot name, e.g., “Inflow,” which matches the slot with that name.
• <slot type> - A slot type, e.g., “SeriesSlot,” which matches all slots of that type.
• dispatch - Any dispatching slots.
There are two ways of specifying a column within multi-column slots:
• <column name> - A specific column name, which matches one of the columns in the selected slot.
• no name - If no name is given, the DMI defaults to the first column.
An account or supply can be specified like so:
• <object name>^<account name>
• <supply name>.Supply - the “.Supply” portion of the string is necessary to tell RiverWare that this is a supply in the accounting system and not a slot in the physical system. If a DMI is used to bring in values, it should be setting supplies in the accounting system rather than accounting slots. See “Setting Slots Versus Setting Supplies” in Accounting for details.
Also, the slots in a Slot Set can be specified using the SlotSet keyword, as follows. See “Slot Sets” in User Interface) for details.
SlotSet.<slot set name>
For example, SlotSet.Reservoir Inflows would expand to all of the slots in the Reservoir Inflows set.
The above slot specifications lead to many ways of specifying the object.slot pairs, as follows:
<object name>.<slot name>.<column name>
<object name>.<slot name>
<object name>.<slot type>.<column name>
<object name>.<slot type>
<object name>.dispatch.<column name>
<object name>.dispatch
<object type>.<slot name>.<column name>
<object type>.<slot name>
<object type>.<slot type>.<column name>
<object type>.<slot type>
<object type>.dispatch.<column name>
<object type>.dispatch
<sub-basin name>.<slot name>.<column name>
<sub-basin name>.<slot name>
<sub-basin name>.<slot type>.<column name>
<sub-basin name>.<slot type>
<sub-basin name>.dispatch.<column name>
<sub-basin name>.dispatch
*.<slot name>.<column name>
*.<slot name>
*.<slot type>.<column name>
*.<slot type>
*.dispatch.<column name>
*.dispatch
<object name>^<account name>
<supply name>.Supply
SlotSet.<Slot Set Name>
These pairs are listed from most exact to least exact. It is possible that more than one control file entry will select a specific object.slot pair in the Workspace. In this case, the more exact entry will always take precedence. For example, in the control file:
# All Confluence objects, Inflow1 slot.
Confluence.Inflow1: file=~/%o.inflow1.dat
# Confluence01 object, Inflow1 slot.
Confluence01.Inflow1: file=~/confluence01.inflow1.dat
Both entries will select Confluence01's Inflow1 slot (the first through an object type, the second through an object name). The more exact entry, the second entry, will take precedence.
There are two other concepts this example introduces: the control file may contain comments (lines beginning with #) and the file name may contain special characters (~ and %), described below.
Finally, note that object and slot names and types must be specified exactly as they appear in the user interface, including case and whitespace.
File Name and Directory Specification
The file name indicates from which data files the object.slots will be imported or to which data files the objects.slots will be exported. The file name may be either relative (beginning with ~/) or absolute (beginning with /). If the file name is relative, then it is relative to the DMI's working directory. The DMI's working directory is where it creates its temporary files. If the RIVERWARE_DMI_DIR environment variable is set, the DMI's working directory is $RIVERWARE_DMI_DIR/dmi_name; otherwise, the DMI's working directory is /tmp/dmi_name. In both cases, dmi_name is the name that appears in the DMI Selector list.
The file name may contain %o and %s directives (currently, it may contain at most one of each). The %o is replaced with the object name, and the %s is replaced with the slot name. These are useful when using object types or slot types in the object.slot specifications.
Note: Because dmi names, object names and slot names are mapped to directory and file names, characters which are not valid in directory and file names (currently all characters other than A-Za-z0-9/_.) are replaced with _ when the directory or file name is created.
Consider the following example:
RIVERWARE_DMI_DIR is /usr/local/riverware
The DMI name is “test dmi”
The control file contains the following entry:
Canal.Flow 1: file=~/%o.%s.dat
The file which the “Tellico Canal.Flow 1" object.slot would import from or export to would be:
/usr/local/riverware/test_dmi/Tellico_Canal.Flow_1.dat
The ~ has been replaced with the value of the working directory, RIVERWARE_DMI_DIR/<dmi name>, %o has been replaced with the object name, and %s has been replaced with the slot name (with the spaces having been replaced with _).
Multiple files can be specified on a single control file line entry for input dmi’s. This enables the user to import data into a slot from two or more files. Use of the data_date file keyword allows the user to specify where in the series slot each file should be placed. The syntax for multiple files is
Object.Slot: file=name file=name
The data files are imported from left to right. If the import = resize is specified, the slot will grow to accommodate the data. Overlapping data is allowed but values will be overwritten by the later data files. If the incoming data does not overlap and there are gaps, any untouched values that existed on the slot will remain.
Another control file available is %tempdir, which is replaced by a guaranteed unique temporary directory. When the DMI is invoked RiverWare generates the directory name, makes the directory and passes the directory to the DMI executable via the RW_DMI_TEMPDIR environment variable. The executable should be able to recognize RW_DMI_TEMPDIR. After the DMI finishes RiverWare removes the directory. The directory name will be similar to the following:
b05741ad-2b57-4f82-8044-bda67606e4c9
Because RiverWare removes the directory you most likely won't see these directories, but if you kill RiverWare or RiverWare crashes a directory might be left behind, in which case you can safely remove it.
Optional keyword=value Pairs
The optional keyword=value pairs provide additional information about the data files the slots will import. (The one exception to this is the file keyword, which identifies the data file itself.) Although the keywords are not case sensitive, the values can be.
The currently supported keywords are:
• file=<data file>
The data file the slot will import from or export to, as described above.
• units=<units>
The units of the data the slot will import or export. <units> must match exactly one of the units defined in the Units List dialog (see “Display Units” in User Interface for details on the Units List).
• scale=<scale> (float)
The scale of the data the slot will import or export.
Note: If either units or scale is not specified in the control file, then it defaults to the current setting in the user interface as specified by the active Unit Scheme; (see “Unit Schemes” in User Interface for details). Since the unit scheme can change from invocation to invocation, it is strongly recommended that the control file always contain units and scale (even if the scale is 1.0).
• precision=<display>|<model>
The precision of the data the slot will import or export. The <display> precision is that specified in the Unit Scheme for the slot. The <model> precision is 17, the same precision as all internal calculations. The default is <display>.
• import=<fixed>|<resize>
This keyword controls how the DMI sets the time series range of the series slot. The default is fixed.
For either import option, the Begin Timestep of the slot is set in the same manner. If the data file contains a start_date header, the slot Begin Timestep is set to the start_date from the data file. If the data file does not contain a start_date header, the slot maintains its existing Begin Timestep.The data import always starts on the new Begin Timestep of the slot with the first value in the data file.
For import=resize, if the data file contains an end_date header, the End Timestep of the time series range of the series slot will be set to the later of the end_date header in the data file or the number of timesteps necessary hold the number of data values in the data file given the updated Begin Timestep of the slot from above. If the data file does not contain an end_date header, the End Timestep of the time series range of the slot will be extended, if necessary, to hold the number of data values in the data file given the updated Begin Timestep of the slot from above. The End Timestep of the slot will never be moved earlier if there is no end_date header in the data file.
For import=fixed, if the data file contains an end_date header, the End Timestep of the series slot is set to the end_date from the data file. Data will not be imported past the new End Timestep of the slot. If the data file does not contain an end_date header and the existing End Timestep on the slot is later than the updated Begin Timestep, the slot maintains its existing End Timestep. Data will not be imported past the End Timestep of the slot. If the existing End Timestep on the slot is equal to or earlier than the updated Begin Timestep, then the slot will be expanded to hold all of the data values in the data file starting with the updated Begin Timestep.
• flags=<true>|<false>
The flags keyword specifies whether or not Series Slot flag values (Input, Target, Best Efficiency, Max Capacity, Drift, and Unit Values) will be exported or imported with the data. The syntax is flags=true; the default is <false>. If an input DMI, the keyword pairs in the data file should be specified as “value flag” with the flag being an integer value, e.g. Input = 1, Output = 2, etc.
• aggregate=<true>|<false>
The aggregate keyword is used to specify whether or not the DMI should import/export all time series slots on an Aggregate Series slot or just the first time series column. If present, with the value “true”, and if the slot indicated is an Aggregate Series slot, the data file is expected to (on import) or will (on export) contain data for all subslots (columns) in the Aggregate Series slot. If the keyword=value pair is absent, or if its value is “false”, only the data for the first subslot (column) of the Aggregate Series slot are present.
When Aggregate Series slot data are imported or exported in total, the data are in row-major format, one timestep per line. The subslots of the aggregation must be homogeneous in start-date, end-date and step size, and all subslots (columns) must be represented on each line.
If used with the ‘flags=true’ keyword-value pair, the data will appear in the form:
value flag value flag value flag...
The flag is an integer number representing the flag. If the named slot is in fact the first subslot (column) of an Aggregate Series slot, the behavior is the same as if the subslot (column) name were absent.
The following three keywords are used to include text string metadata. They are mutually exclusive; you can only specify one at a time.
• slot_anno = <true>|<false>
The slot_anno keyword indicates whether to import or export series slot notes; see “Exporting Notes Using DMIs” in User Interfacefor details. The default value for slot_anno is false, meaning no Notes will be written.
• slot_set_info = <true>|<false>
The slot_set_info keyword indicates whether to export series slot value information. The default value for slot_set_info is false, meaning no information will be written.When true, the information corresponds to the tool tips seen on slot values on slot and SCT dialogs () will be written to the file; see “Series Slots” in User Interface for details. The string appears after the value. Examples of the information are “Set by DMI: Input DMI", “Set by Rule: (7) Flood Control”.
• slot_opt_sol_info = <true>|<false>
The slot_opt_sol_info keyword indicates whether to export series slot optimization solution information . The default value for slot_opt_sol_info is false, meaning no information will be written. When true, the available per slot/value optimization solution information will be written to the file. The string appears after each value. Examples of the information are “Frozen at Lower Bound”, or “Frozen by (3) Minimum Load 47.6% between limits set by 3.1.1.1 and 2.1.1.1.”. See “Tooltips on Variables” in Optimization for details.
User keyword=value Pairs
The user keyword=value pairs provide an additional means by which the user can pass parameters to the DMI executable. The user keyword=value pairs are specified in the control file as:
!keyword=value
The keyword=value pairs are written to the metaControl file, with the ‘!’ removed, on all lines they apply to. The DMI executable can then use the keyword=value pairs to influence its behavior.
Example 2.1
#
# All LevelPowerReservoir Outflows
#
LevelPowerReservoir.Outflow: file=~/%o.Outflow units=cfs scale=1.0
#
# All LevelPowerReservoir Pool Elevations,
# but for Hiwassee use a different scale.
#
LevelPowerReservoir.Pool Elevation: file=~/%o.%s units=ft scale=1.0
Hiwassee.Pool Elevation: file=~/%o.%s units=ft scale=10.0
#
# All LevelPowerReservoir Storages.
#
LevelPowerReservoir.Storage: file=~/%o.%s units=cfs-day scale=1.0
#
# All LevelPowerReservoir Hydrologic Inflows.
#
LevelPowerReservoir.Hydrologic Inflow: file=~/%o.%s units=cfs scale=1.0
#
# Finally, all SeriesSlots which are not selected by one of
# the preceding lines. (Remember that *.<slot type> is the
# least exact specification.) The file ~/start_end is a data
# file which contains only the start_date: and end_date:
# attributes. This will serve to change the start date and
# end date for all series slots which import this file.
#
*.SeriesSlot: file=~/start_end
Data Files
The data files are the files from which the slots will be imported or to which the slots will be exported. They contain both the data attributes and data values. The attributes are specified as keyword:value pairs, and all attributes must come before the first data value. Although the keywords are not case sensitive, the value in the keyword:value pair can be.
The currently supported keywords are:
• The start date of a series slot:
start_date: yyyy-mm-dd hh:mm
start_date: 1996-04-15 06:00
• The end date of a series slot:
end_date: yyyy-mm-dd hh:mm
end_date: 1996-04-22 06:00
• The start date of where the data should be imported.
data_date: yyyy-mm-dd hh:mm
data_date: 1996-10-22 06:00
data_date specifies where in the series slot the data is to be imported. Implicitly, data_date is only useful with input DMIs. It was designed for use with the multiple data file feature in control files: Object.Slot: file=... file=... in which data files are imported from left to right. If all data files were imported at the beginning of the series slot then values from later data files would overwrite values from earlier data files. Therefore, all data files (except possibly the first) should contain the data_date keyword, to import their values at the correct location in the series slot and to prevent their values from overwriting values from earlier data files.
• The timestep of the data being exported from a series slot:
timestep: <count> <timestep>
<count> is an integral value.
<timestep> is one of HOUR, DAY WEEK, MONTH, YEAR.
timestep: 6 HOUR
• The units of the data in the data file.
units: units
units: acre-feet/month
For multi-column table slots:
units: <column 0 units> <column 1 units> ...
units: ft cfs
• The scale of the data in the data file.
scale: scale
scale: 100
For multi-column table slots:
scale: <column 0 scale> <column 1 scale> ...
scale: 1 1000
• The new display units for the slot importing the data. Also, if the units keyword is not specified, then the units of the data being imported is the new_units:
set_units: new_units
set_units: cms
• The new scale or the slot importing the data. Also, if the scale keyword is not specified, the scale of the data being imported is the new_scale.
set_scale: new_scale
set_scale: 10
• The new Lower Bound for the slot. In the units and scale specified on the slot.
set_min: new_min
set_min: 10
• The new Upper Bound for the slot. In the units and scale specified on the slot.
set_max: new_max
set_max: 1000
• The new Optimization Min Value for the table slot. In the units and scale specified on the slot.
opt_min: <column 0 min> <column 1 min> ...
opt_min: 10 10
• The new Optimization Max Value for the table slot. In the units and scale specified on the slot.
opt_max: <column 0 max> <column 1 max> ...
opt_max: 10000 100000
• The new display format of the slot importing the data.
display_format: <new_format>
<new_format> is one of float, integer, scientific.
display_format: scientific
• The new display precision of the slot importing the data.
display_precision: new_precision
display_precision: 4
• The new period of the periodic slot importing the data.
periodic_period: <count> <timestep>
<count> <timestep> is one of 6 HOUR, 12 HOUR, 1 DAY, 1 MONTH, N YEAR where N is 1 to 99.
periodic_period: 2 YEAR
• The new base year for the multi-year periodic slot importing the data.
periodic_base: new_year
periodic_base: 1998
• The new interval type for the periodic slot importing the data.
periodic_interval: <new_interval_type>
<new_interval_type> is one of regular, irregular.
periodic_interval: irregular
• The new interval size for the regular periodic slot importing the data.
periodic_regular_size: <count> <timestep>
<count> <timestep> is one of 1 HOUR, 6 HOUR, 12 HOUR, 1 DAY, 1 MONTH.
periodic_regular_size: 1 MONTH
• The new data interpolation method for the periodic slot importing the data.
periodic_data_interp: <new_method>
<new_method> is one of lookup, interpolate.
periodic_data_interp: lookup
• The new header units for a periodic slot with numeric column headers that is importing data.
column_units: new_units
column_units: cfs
• The new header scale for a periodic slot with numeric column headers that is importing data.
column_scale: new_scale
column_scale: 10
• New symbolic row dates for the irregular periodic slot that is importing the data.
periodic_rows: <new_row_dates>
<new_row_dates> is a space separated list of <symbolic_date> entries.
<symbolic_date> takes the form of minute/hour/day/month/multi-year index, where each piece is represented by an index number (minute (0), hour (0-23), day (1-31), month (1-12), year (1-99)). Symbolic dates need only be complete to the longest appropriate interval for the period of the particular slot. For example, 0/3 is 3:00, 0/3/21 is 3:00 Day 21, 0/3/21/4 is 3:00 April 21, and 0/3/21/4/2 is 3:00 April 21, Year 2.
periodic_rows: 0/0/16/2 0/0/2/3 0/0/16/6 0/0/2/10 0/0/16/12
• New column header numbers for a periodic slot with numeric column headers that is importing data.
periodic_columns: <new_column_entries>
<new_column_entries> is a space separated list of numeric values.
periodic_columns: 1000 4000 10000 40000 100000
The data values are specified either one per line (for series, list, and scalar slots) or one row per line (for table and periodic slots). For table slots, the row may include a new row label before the data values. If the label contains spaces, it must be enclosed in double quotes. As with the control file, the data files may contain comments (lines beginning with #).
Series slot notes (see “Notes on Series Slots” in User Interface) can also be represented in data files for import or export. They are specified as:
<value> anno {NoteGroup} {Note}
where <value> will be a numeric value, “anno” is a keyword, NoteGroup is the name of the NoteGroup and Note is the actual note. The “<“ and “>” will not exist in the file, while the “{“ and “}” do exist, delimiting the Note Group name from the note text itself. For Example, a line in the file might be:
102.031 anno {Storm Events} {4.3 Inches}
where Storm Events defines the Note Group to which the note belongs and 4.3 Inches is the note itself.
DMI Executable
The DMI executable is invoked by RiverWare, which then waits for it to exit. For an import DMI, the executable creates data files from an external data source. For an export DMI, the executable populates an external data sink from data files.
Nearly any programming language can be used to write the DMI executable. Often the choice of tools will be based on user experience and existing tools that can communicate with the database.
Note: A Windows batch (.bat) script could work as a DMI executable. It does need to include an exit statement: exit /b 0 The convention for a DMI executable is a zero exit status indicates success, a non-zero exit status indicates an error. Without the exit statement the bat script would return the “DMI executable failed: Exited with 1." error.
The DMI executable is passed the following command line arguments:
Meta-control File
The path to the meta-control file. The meta-control file is a copy of the control file described above, with wildcards resolved. Each line is of the form:
object.slot: file=<file name> [optional keyword=value pairs]
The DMI executable should use the object.slot specification to determine for which objects and slots it must provide data (import DMI), or for which objects and slots data is being provided (export DMI). The executable should use the file specification to determine to where to write the data to be read by RiverWare (import DMI), or from where to read the data exported by RiverWare (export DMI).
Working Directory
The working directory is the DMI's working directory, as described above. It is an artifact of an earlier implementation and can safely be ignored by the DMI executable.
Start Data (YYYY-MM-DD)
The start date of the data the executable must provide (import DMI), or of the data which is being provided (export DMI).
Start Time (HH:MM)
The start time of the data the executable must provide (import DMI), or of the data which is being provided (export DMI).
End Data (YYYY-MM-DD)
The end date of the data the executable must provide (import DMI), or of the data which is being provided (export DMI).
End Time (HH:MM)
The end time of the data the executable must provide (import DMI), or of the data which is being provided (export DMI).
Timestep (6HOUR)
The timestep of the data the executable must provide (import DMI), or of the data which is being provided (export DMI).
System Parameters
Not implemented.
User Parameters
The user parameters, in the form: -Ukeyword=value The intention of the user parameters is described above.
DMI Editor Dialog
The DMI Editor dialog enables the user to edit the DMI name, type, control file path, executable file path and other configuration options.
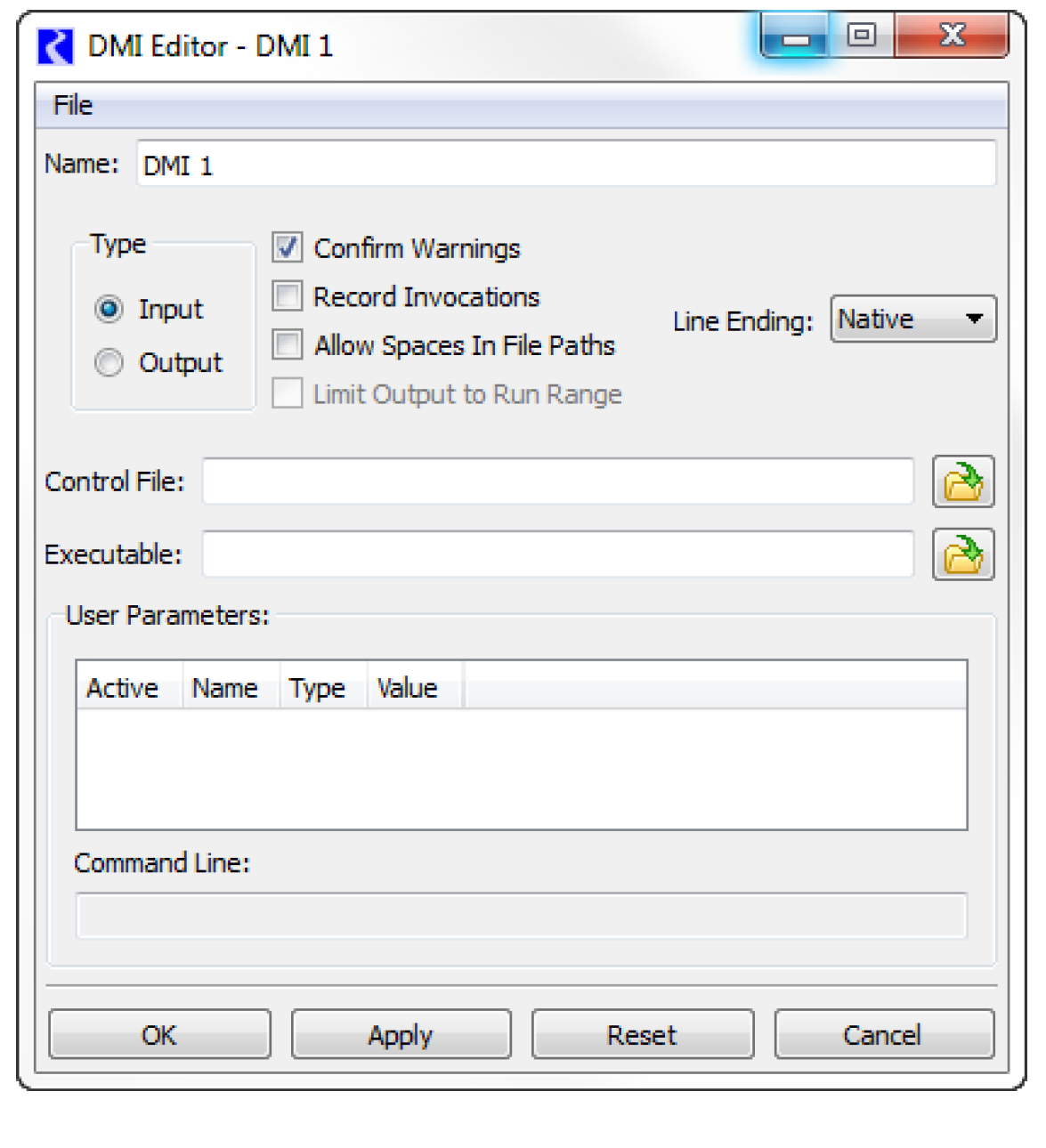
Name
To edit the DMI name, the user selects the Name field to edit the name in place:
When the edits are applied the new DMI name is validated; the possible errors are:
• A blank name
• A duplicate name (the same name as another DMI)
Type
To edit the DMI type, the user selects the appropriate Type.
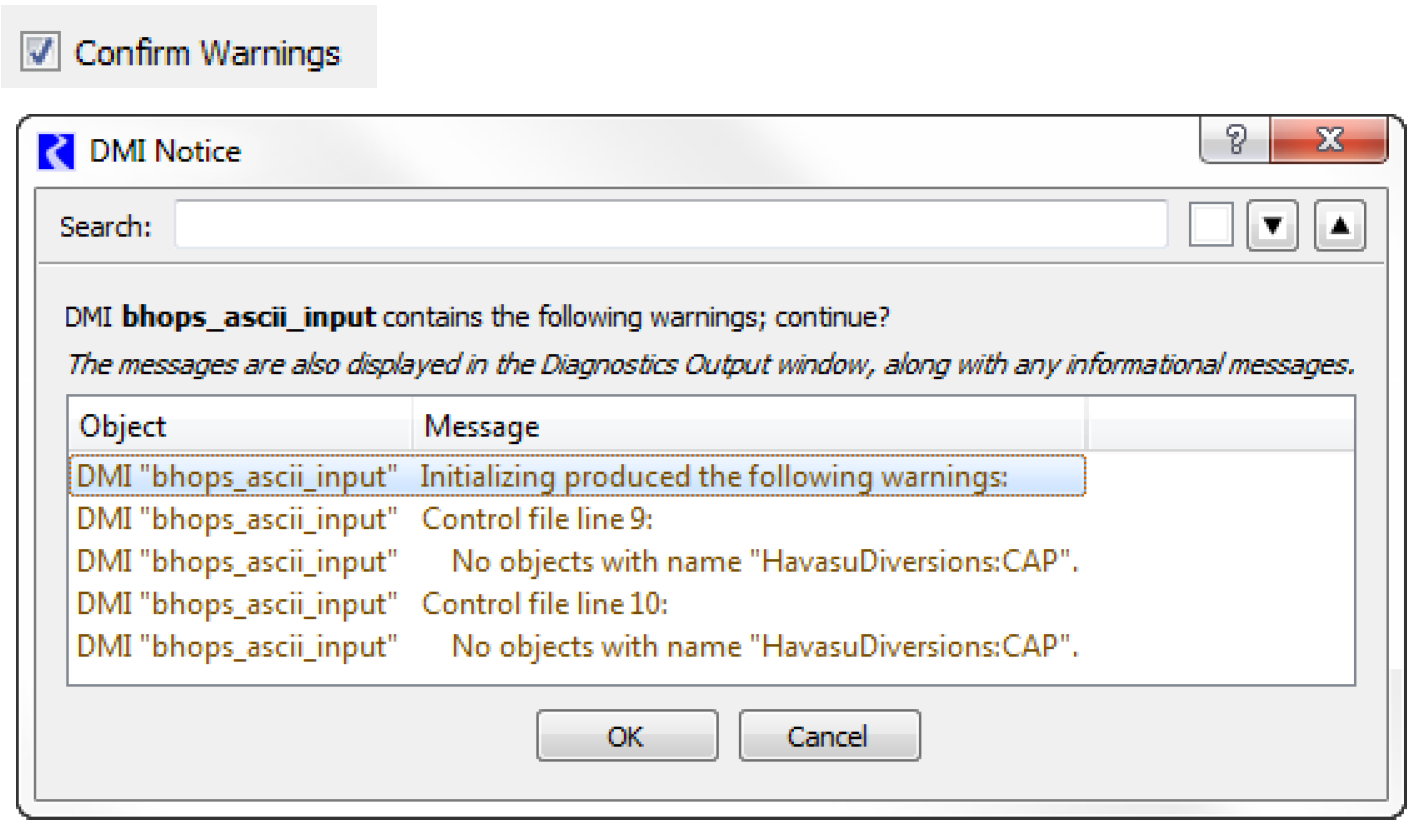
Confirm Warnings Checkbox
The Confirm Warnings check box controls whether you wish for the DMI to continue when warnings are generated. If Confirm Warnings is selected, the user is prompted to confirm any warning messages that appear; if not checked, the DMI continues after any warnings. Figure 2.2 is a sample dialog that appears during execution when the Confirm Warnings check box is selected.
Figure 2.2
Record Invocations
The Record Invocations check box allows RiverWare to maintain information which chronicles input DMI invocations. With this information, values set by DMIs can be cleared on a per-invocation basis.
If a user wishes to clear all values that are input by a DMI, this box should be checked. If a user knows values set by a particular DMI won’t be cleared then it is not necessary to maintain information about the DMIs invocations and this box should remain unchecked. (The information occupies memory and could, over time, degrade performance.)
The check box is only enabled for input DMIs and the default is unchecked. See “DMI Invocation Manager Dialog” for details on clearing values set by an input DMI.
Note: When the Record Invocations box is checked, series values imported by the input DMI are given the “Z” flag indicating they were set by a DMI.
Allow Spaces in File Paths
The Allow Spaces in File Paths allows the user to specify paths that have spaces. Without this box checked, the DMI would replace spaces in paths with ‘_’.
Note: If users have written their DMI executable to recognize white space as the end of a path, and they begin using spaces in path names, then the executable should be modified.
Limit Output to Run Range
The Limit Output to Run Range toggle allows the user to specify that output data should only be written for the run range (Start Timestep to Finish Timestep). Without this box checked, the DMI will write the entire series of data. This configuration is only available for Output DMIs.
Line Ending
The Line Ending menu allows the user to specify the type of line ending sequence to write for output DMIs. This option is useful when you are running RiverWare on one platform, e.g. Windows, but your output data processing utilities and scripts are on another platform, e.g. Solaris.
The choices are:
• Native (default, uses the format for the current platform)
• Windows (CR NL)
• Unix (NL)
CR = carriage return, NL = newline
Control File
To edit the DMI control file, the user either:
• Selects  to open a file chooser dialog and selects the control file
to open a file chooser dialog and selects the control file
to open a file chooser dialog and selects the control file• Selects the Control File field to edit the control file in place

The control file can contain environment variable references of the form:
• $VARIABLE
• $(VARIABLE)
• ${VARIABLE}
VARIABLE is a letter followed by zero or more letters, digits or underscores. If the variable is followed by a letter, digit or underscore it must be “quoted” with () or {}. For example:
• $DMI_DIR/Control/Res.ctl
• $(DMI_DIR)_$TARGET/Control/Res.ctl
When the edits are applied the control file is validated; the possible errors are:
• A blank control file
All other validation occurs when the DMI is invoked, including:
• Replacing environment variable references with their values
• Verifying the resulting path refers to a readable file
Executable
To edit the DMI executable file, the user either:
• Selects  to open a file chooser dialog and select the executable file
to open a file chooser dialog and select the executable file
to open a file chooser dialog and select the executable file• Selects the Executable field to edit the executable file in place

Note: Alternatively, the user can create the DMI Data Files separately without using an executable. In this case the executable field can be left blank.
The executable file can contain environment variable references, the same as the control file.
All validation occurs when the DMI is invoked, including:
• Replacing environment variable references with their values
• Verifying the resulting path refers to an executable file
User Parameters
To edit the DMI user parameters the user specifies:
• If a parameter is active (e.g. if it should be included on the DMI executable’s command line)
• If a parameter is active, its value
 indicates an inactive parameter;
indicates an inactive parameter;  indicates an active parameter; by default parameters are inactive:
indicates an active parameter; by default parameters are inactive:The user toggles a parameter’s active state by selecting the Active cell; when a parameter is active its value is displayed in the Value cell.
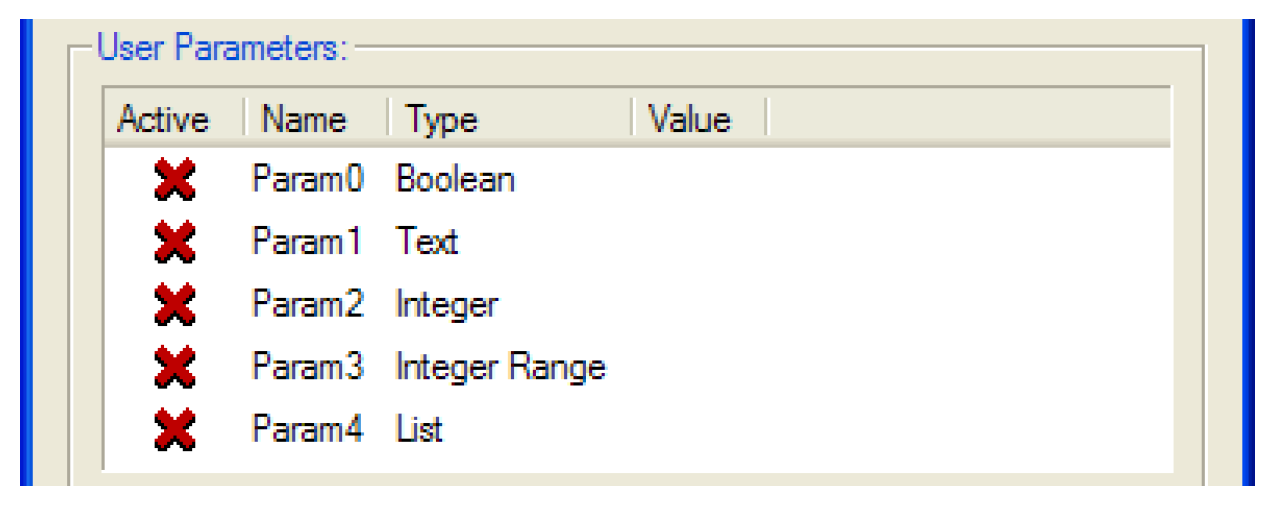
The user edits a parameter value by clicking twice in the Value cell, activating a control appropriate for the parameter type.

For a Boolean parameter the control is a menu containing False and True.
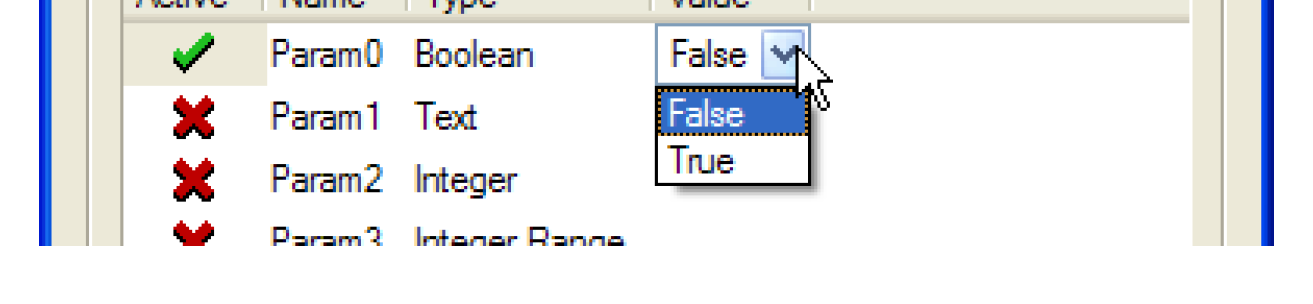
For a Text parameter the control is a one line text editor. When the edits are applied the parameter’s value is validated; the possible errors are as follows:
• The value is blank
• The value contains white space

For an Integer parameter the control is an unbounded integer spinner. For an Integer Range parameter the control is an integer spinner, bounded by the parameter’s minimum and maximum values.

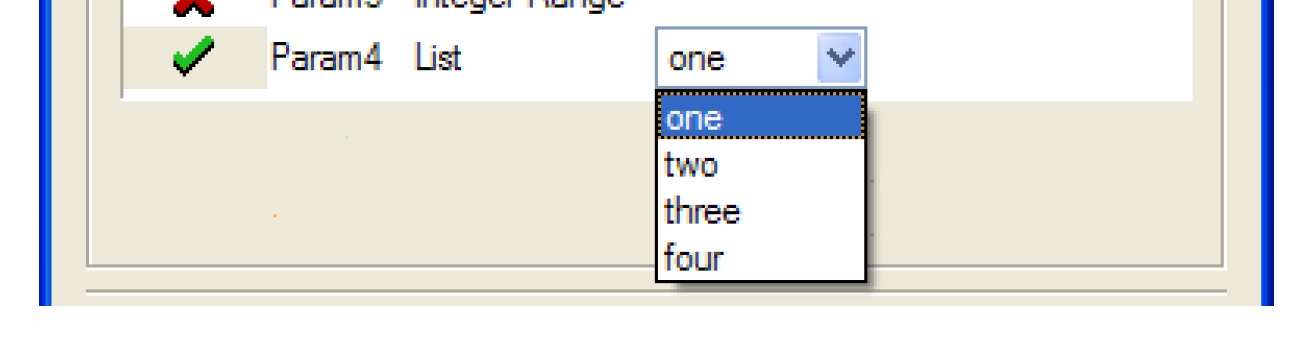
For a List parameter the control is a menu containing the list items defined in the DMI Parameter dialog.
Command Line
As the user edits the user parameters they are displayed as they will appear on the DMI executable’s command line:
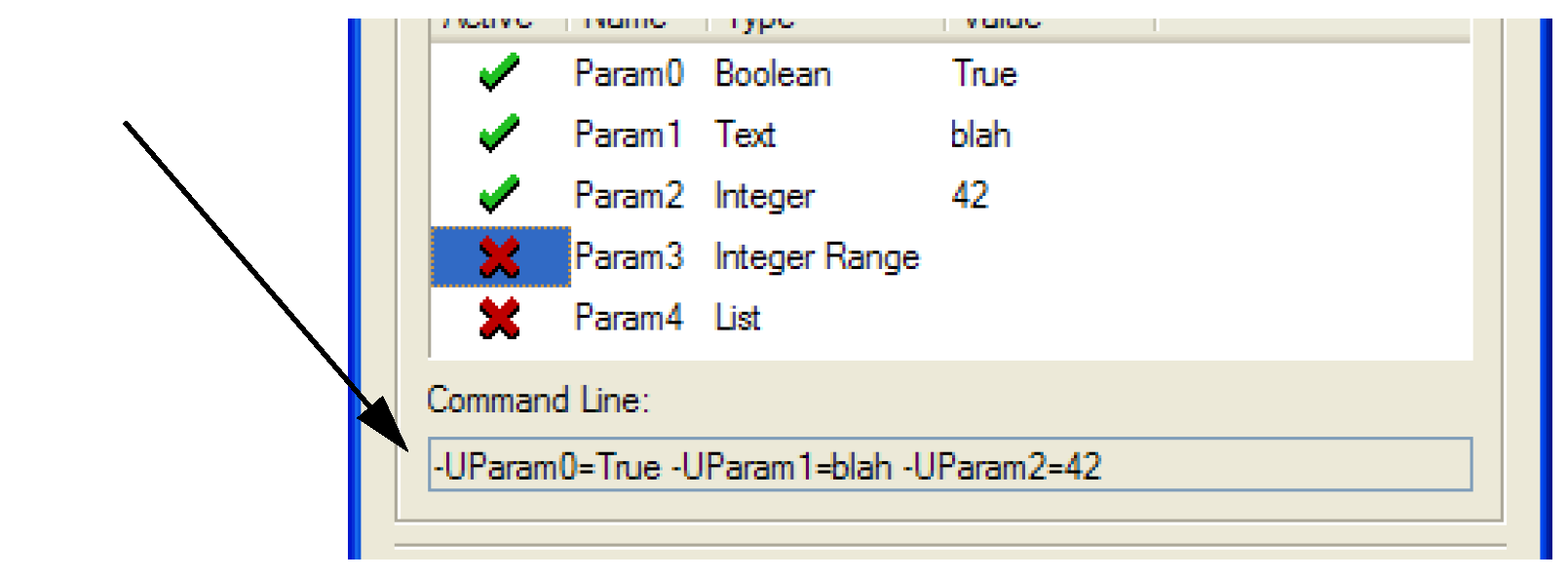
The command line is not editable, but it can be horizontally scrolled, copied-and-pasted and dragged-and-dropped (to a Microsoft Word document, for example).
Revised: 11/11/2019